



Alerting
Receive alerts via email, text, Slack, and more. Update alert criteria based on a dynamic list in a lookup table.
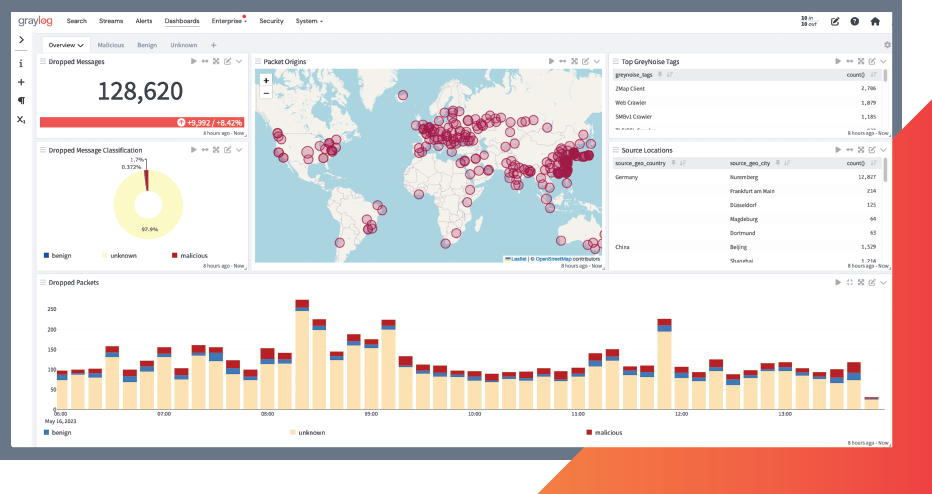
Graylog Operations is built on the Graylog platform for IT, Network, and DevOps professionals. Available in a self-managed or cloud experience, Graylog Operations offers a powerful, flexible, and seamless centralized log management experience. You have increased visibility into day-to-day operations to gain meaningful context from volumes of event log data, pinpoint errors, take action faster, and improve key metrics like Mean Time To Detect (MTTD) and Mean Time To Respond (MTTR).
Get to the root cause of performance issues and bottlenecks faster.
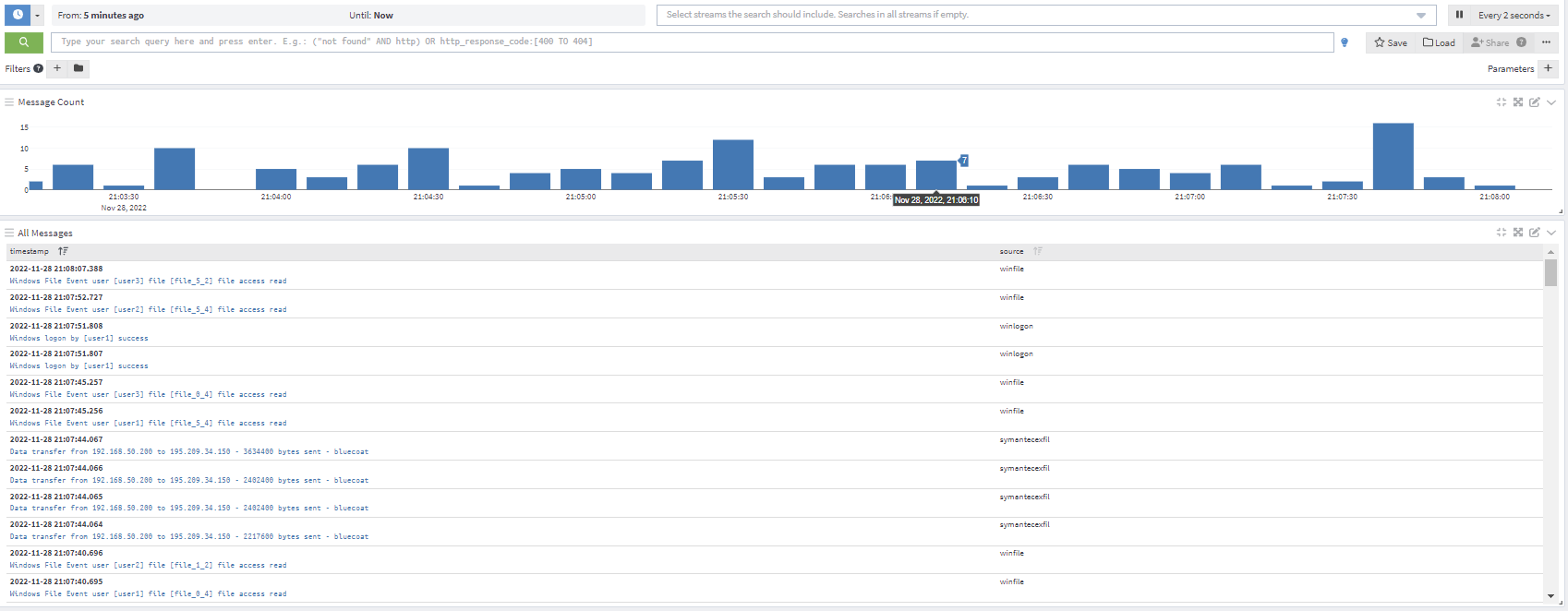
Parse terabytes of data in seconds for faster troubleshooting.
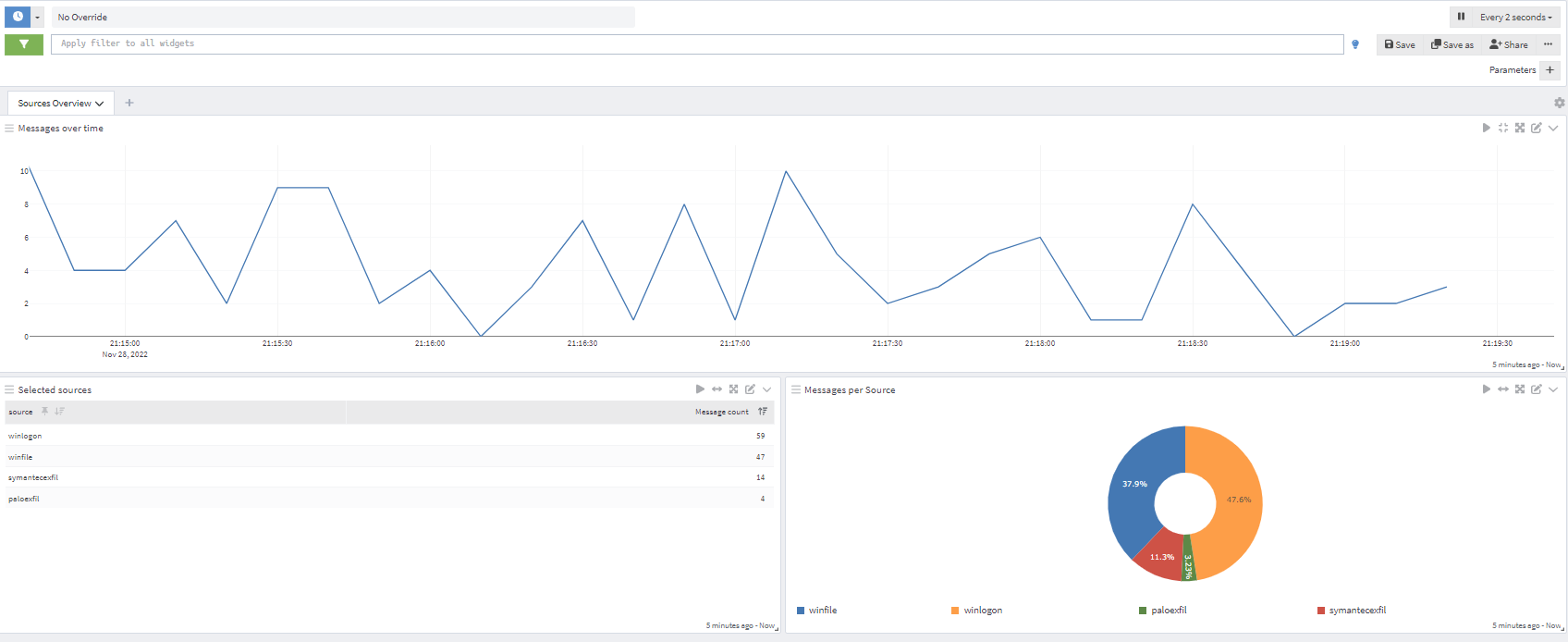
Filter out the noise so you can focus on the events that really matter.
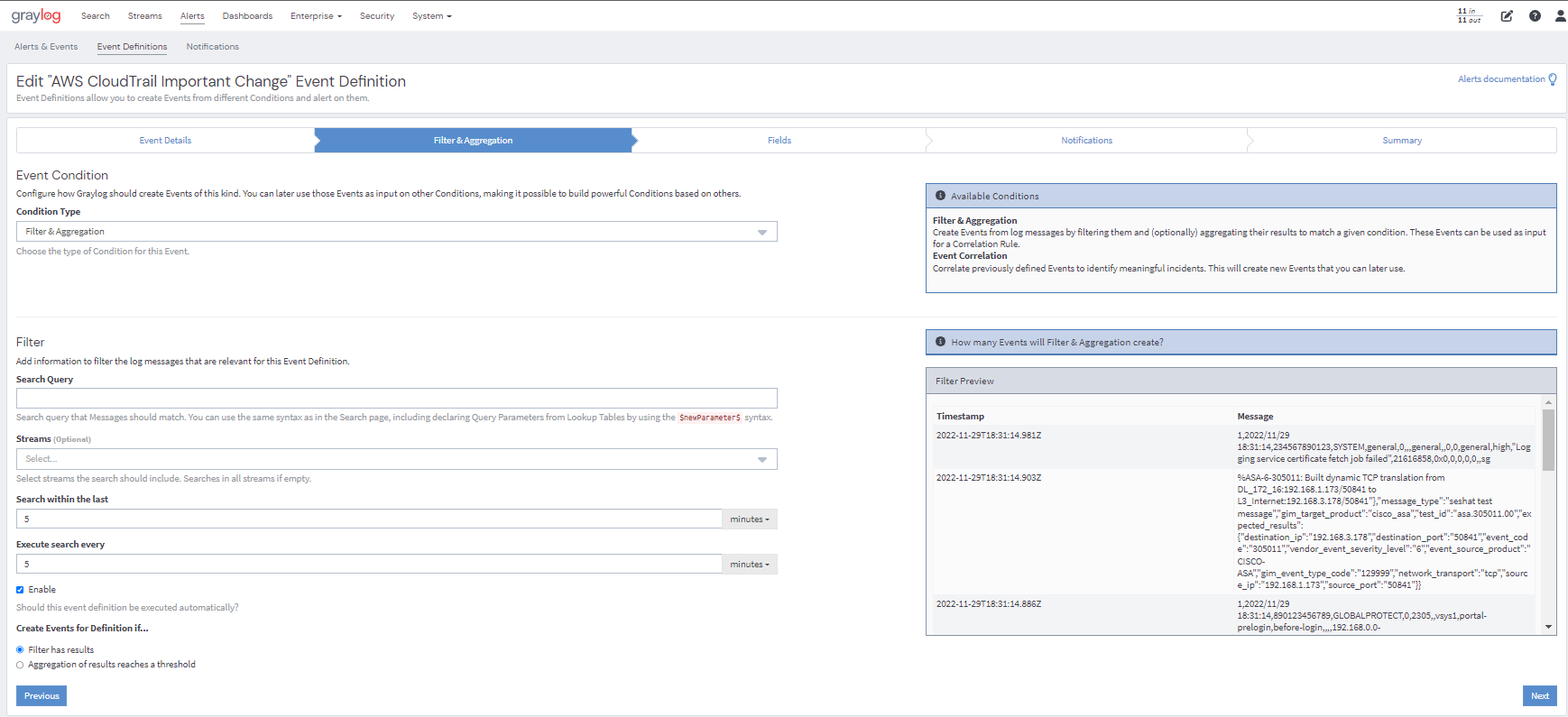
Start fixing issues before they impact your customers.

Get immediate value for your logs with cloud-native capabilities, intuitive UI, and out-of-the-box content. Compared to other log management solutions, Graylog gives you what you need to manage the day-to-day and the unexpected while your organization grows and changes without fear of licensing costs.

1. Increased visibility across your IT environment
2. Search volumes of log data in seconds
3. Get alerts for the issues that matter
4. Increase productivity with powerful automation
5. Improve key metrics like MTTD and MTTR
Purpose-built for modern log analytics, the capabilities and features of Graylog Operations help remove complexity from day-to-day analysis activities like data exploration and error tracing so you can quickly and easily find meaning in data and take action faster.
Receive alerts via email, text, Slack, and more. Update alert criteria based on a dynamic list in a lookup table.

Store older data on slow storage and easily re-import it into Graylog when you need it.

Track who accessed what log data and what actions they took against it to ensure compliance and security.

Get email, text, Slack, or other message type alerts on single, combined, or missing events.

Combine widgets to build customized data displays and automate the delivery of reports to your inbox.

Perform faster research by adding WHOIS, IP Geolocation, threat intelligence, or other structured data.

Easily send data to Graylog Cloud or to an on-premise Graylog Server installation.

Start fast with prebuilt content — search templates, dashboards, correlated alerts, reports, dynamic look-up tables, streams & pipelines, and more.
Easily share data with other business-critical systems for full transparency and collaboration.

View data in real-time, ensure continued availability, streamline investigations.

Build complex queries in minutes with Graylog’s web console - no proprietary query language needed.

Leverage Graylog’s dashboard functionality to easily build and configure scheduled reports.
Easily integrate your data into 3rd party systems to automate reporting, workflow and research.

Enter one or more criteria for a more comprehensive search or dashboard view. Easily save and share parameterized searches and dashboards.

Build and combine multiple searches for any type of analysis into one action and export results to a dashboard.

Route log messages into categories in real time and control data processing by tying streams to your pipelines.

Control entity access and capabilities. Includes LDAP/Active Directory integration.
"Powerful and real-time log management platform."



At Graylog, we want you to get all your questions answered before you buy. Still undecided? Schedule your Graylog Operations demo today and see our powerful log management platform in action.
Get the latest in log management, security, and all things Graylog delivered to your inbox once a month.
Follow Us:
© 2024 Graylog, Inc. All rights reserved