INTRODUCTION
So you have been adding more and more logs to your Graylog instance, gathering up your server, network, application logs, and throwing in anything else you can think of. This is exactly what Graylog is designed for, to collect all the logs and have them ready for you to search through in one place.
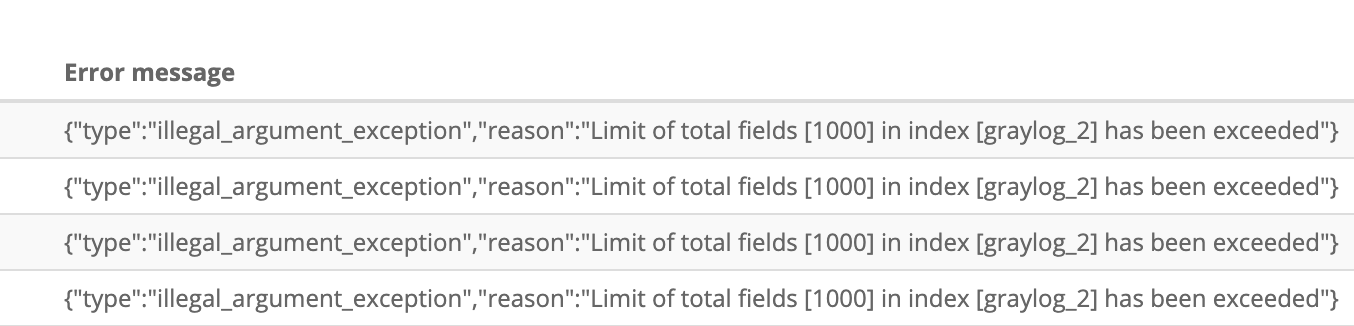
Unfortunately, during your administration of Graylog, you go to the System -> Overview screen and see the big bad red box, saying you are having indexing failures.

After clicking on the “Show errors” button you get to the messages as shown below, where it is saying that an index has too many fields. By default, Elasticsearch has a 1000 field max to prevent data explosion and creating millions of fields, but for our case, we need to get more than the allotted one thousand.
OVERVIEW
As mentioned above, Elasticsearch keeps the default to 1000 fields to limit the exponential growth of data it is indexing. If this is happening to you, you might be putting many different types of data into the same index, thus breaking the 1000 limit. In my case, I had a few types of logs going into the “graylog_2” index. I had Windows Logs from winlogbeat, packetbeat logs, my fileserver, and wireless access points all going to the same indices.
The best practice is to keep your log types in different indices, so like type messages are stored together making searching more efficient in large data sets. I ended up creating new indexes for my packetbeats and Windows data to give them their own storage location. This also allowed me to set up retention times for each, keeping my Windows data for 1 year, and my packetbeat data for 30 days.
But let’s say you really do need everything in one index or have a LOT of fields for some reason.
DIGGING IN
First, we need to find out how many fields we need if we want to increase the limit. To do that, we need to get to a command line, and run the following command:
curl -XGET ‘localhost:9200/graylog_2/?pretty’ | grep type | wc -l
This is going to query the local box, and in my case, ‘graylog_2’ index, find the number of lines with the word type and give you an output. We would have to change ‘graylog_2’ to your index having the error to get the right number. Type, which I searched for, would be the data type in the Elasticsearch fields. This could be something like “long, keyword, boolean, float”. Once I ran this command I found I had 1123 fields.

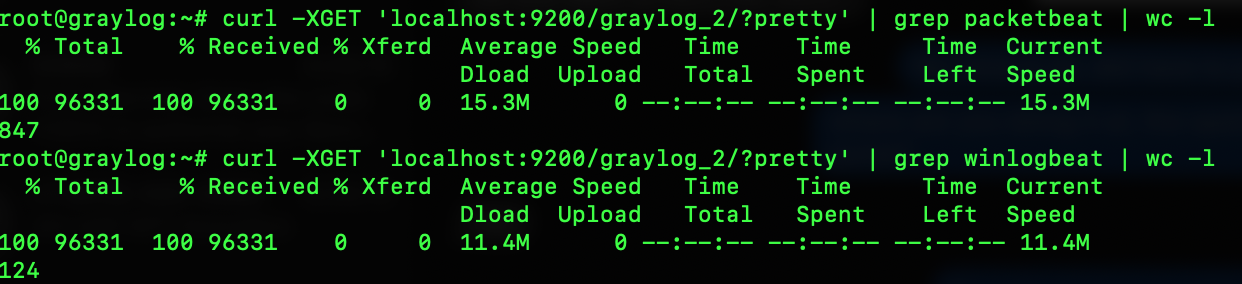
I wanted to find out a bit more of what was causing me to have so many fields, so I changed the grep to my other known fields. First I did one for `packetbeat` and second for `winlogbeat` to see how many fields each were producing, finding that packetbeat was the big culprit of 847 fields itself, and Windows only 124.
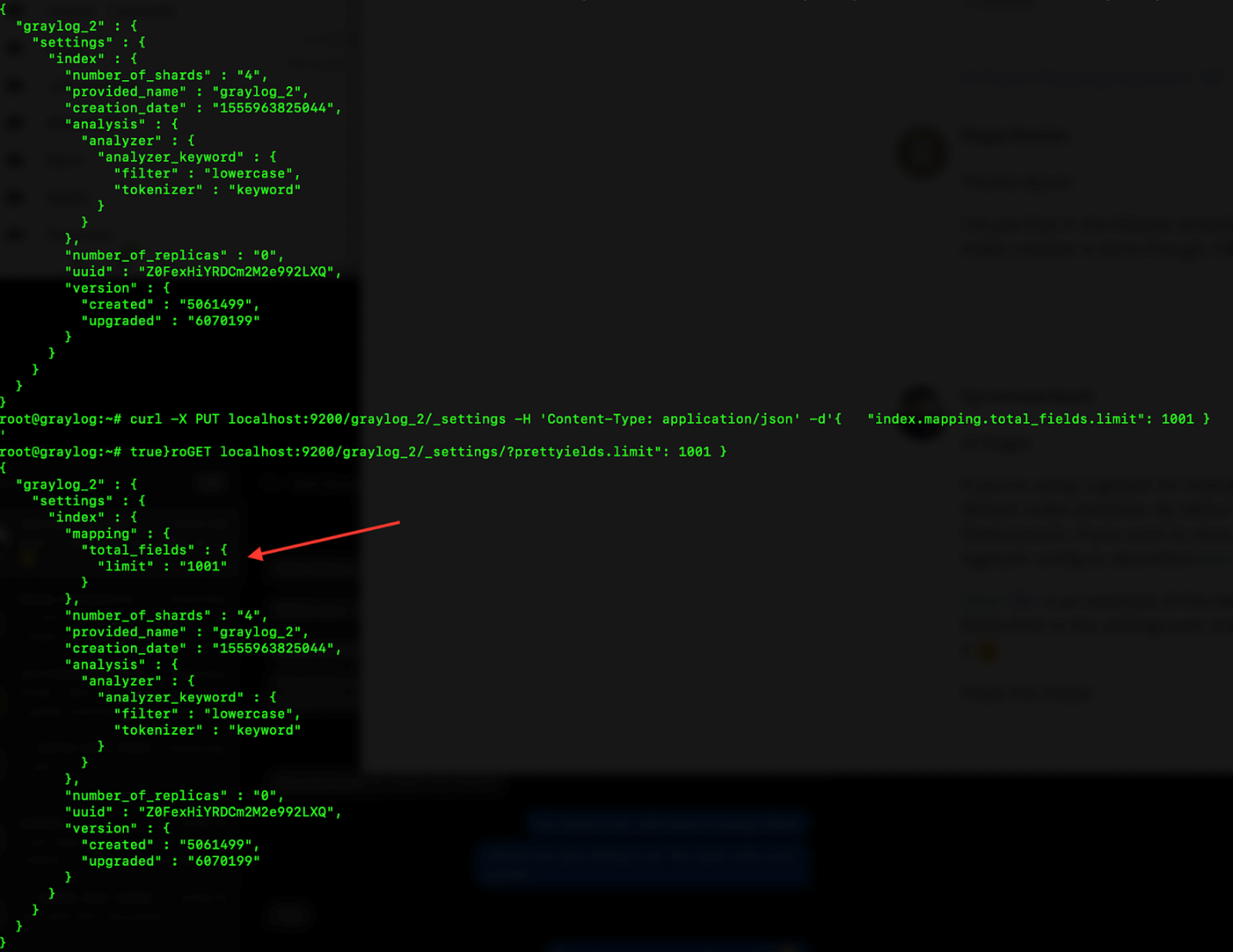
With this information, I decided to move packetbeats and windows to their own index, but if you wanted to just expand the number of fields, we would take the next step of adding in the command below. NOTE: This command changes from 1000 to 1001 fields is for illustration purposes, if I was keeping all my data in one index, I would have picked something over the fields we found before 1123.
curl -X PUT localhost:9200/graylog_2/_settings -H ‘Content-Type: application/json’ -d'{ “index.mapping.total_fields.limit”: 1001 } ’
After running this one-line command, you can verify the new limit is by running the following command
curl -XGET localhost:9200/graylog_2/_settings/?pretty
Here is what it looked like before and after I ran the commands:
CONCLUSION
While adjusting the number of fields in an index is possible, as shown above, it is something to take into consideration, and not increase the number too drastically. When you have too many fields, you can have what is called mapping explosion, causing out of memory errors and difficult situations to recover from, While there is no firm number to say don’t cross, keeping the number as close to 1000 as possible is advised, as each mapping takes some RAM and disk. It is more efficient to create another index and send your data into it via Streams.
