
There are multiple ways to perform log file parsing: you can write a custom parser or use parsing tools and/or software. Parsers can be written in many programming languages; some are better for this task than others, but the choice often depends on what language you are most comfortable with.
In this article, we will talk about log file parsing process in Graylog and give examples of parsers in several different languages, as well as compare Graylog with Splunk in terms of parsing.
All About Parsing Log Files
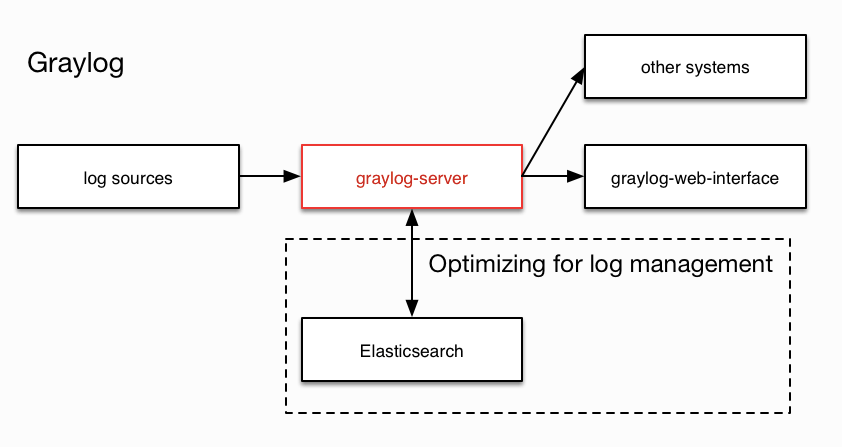
HOW TO PARSE A LOG FILE IN GRAYLOG
Since not all devices follow the same logging format, it is impossible to develop a universal parser. For devices that don’t comply with Syslog format rules, Graylog overrides this issue using pipelines and extractors. Log file parsing is done by a combination of raw/plaintext message inputs, extractors, and pipeline processors. The built-in raw/plaintext inputs allow you to parse any text that you can send via TCP or UDP. No parsing is applied at all by default until you build your own parser. Let’s discuss what extractors are and why they were created in the first place.
EXTRACTORS
Syslog (RFC3164, RFC5424) has been a standard logging protocol since the 1980s, but it comes with some shortcomings. Syslog has a clear set of rules in its RFCs that define how a log should look like. Unfortunately, there are a lot of devices such as routers and firewalls that create logs similar to Syslog but non-compliant with its RFC rules. For example, some use localized time zone names or omit the current year from the timestamp, which causes wrong or failed parsing.
One possible solution was to have a custom message input and parser for every format that differs from Syslog, which would mean thousands of parsers. Graylog decided to address this problem by introducing the concept of Extractors in the v0.20.0 series.
The extractors allow users to instruct Graylog nodes about how to extract data from any text in the received message (no matter which format or if an already extracted field) to message fields. This allows for more elaborate queries like searching for all blocked packages of a given source IP or all internal server errors triggered by a specific user.
You can create extractors via Graylog REST API calls or via the web interface using a wizard.
PIPELINE PROCESSORS
Pipeline Processors are the preferred method of parsing logs flowing into Graylog allowing for greater flexibility in routing and enriching a message before writing to disk. Pipeline processors can be used to call external functions line Geo-Location or Lookup tables to add additional context around data at ingestion time.
Pipelines are a set of rules grouped in stages, allowing a message to flow through each stage for processing. Each pipeline can be set to multiple streams of data to allow for great control of the processing each log gets.
DECORATORS
Finally, if your message does not get parsed correctly on the way into Graylog before it is written to disk you can use decorators. Decorators allow you to change the messages fields during search time while preserving the unmodified message on disk.
BUILT-IN FORMATTING
Some of the agents sending in log data will pre-format the logs so Graylog can create a pre-formatted view without any further modification. Many devices can support a standardized format like GELF, or have the Graylog Sidecar manage agents like a beats or NXLog agent.
GELF
The Graylog Extended Log Format (GELF) is a log format made to improve some standard Syslog flaws.
Plain Syslog Shortcomings:
- Limited to 1024 bytes
- No data types in structured Syslog
- Too many Syslog dialects to successfully parse all of them
- No compression
Improvements on these issues make GELF a great choice for logging from within applications. Graylog marketplace offers libraries and appenders for easily implementing GELF in many programming languages and logging frameworks. GELF can be sent via UDP so it can’t break your application from within your logging class.
WRITING CUSTOM LOG FILE PARSERS
If you don’t want to use Graylog or any other tool, you can write your own custom parser using a number of languages. Here are some commands and methods used in Java, Linux, Python, and PowerShell:
JAVA PARSE LOG FILE
This is the method to use if you do your own parsing using Java:
STRING.SPLIT METHOD
The Split method splits a string around matches of the given regular expression. The array returned by this method contains each substring of this string that is terminated by another substring that matches the given expression or is terminated by the end of the string. The substrings in the array are in the order in which they occur in this string. If the expression does not match any part of the input then the resulting array has just one element, namely this string.
If you don’t want to spend time writing your own parser, there are many parsing tools available for Java. You can use a library to implement GELF in Java for all major logging frameworks: log4j, log4j2, java.util.logging, logback, JBossAS7, and WildFly 8-12.
LINUX PARSE LOG FILE
You can perform command line log analysis in Linux, and these are some of the most useful commands:
HEAD AND TAIL
If you want to display a certain number of lines from the top or bottom of a log file, you can use head or tail to specify that number. If you don’t add a value, the default value is 10 lines.
GREP
The grep tool is used to search a log file for a particular pattern of characters. This tool, in combination with regular expressions, is the basis for more complex searches.

SURROUND SEARCH WITH GREP
One example of advanced search using Grep is surround search. The B flag determines the number of lines before the matching line and the A flag determines the number of lines after the matching line you want to show.

PYTHON PARSE LOG FILE

You can create a custom log file in Python by using regex. This is an example of parsing by line.
Open instruction opens the defined log file path using read-only access (“r”) and assigns the data to the file variable. The for loop goes through the data line by line, and if the text in line matches regex, it gets assigned to the match variable as an object.
To parse more than one line at a time, you can assign the whole file’s data to a variable using data = f.read().

In this example, you can choose whether to parse by line (if read_line is True) or by file (if read_line is False). The matching algorithm is the same, with the only difference in the data that is compared with regex (line or whole text).
For more complex parsing, there are a plethora of parsing tools you can use for free. There is a great list of Python parsing tools on GitHub you can check out here.
POWERSHELL PARSE LOG FILE
If you perform log file parsing with PowerShell, this is arguably the most useful command to write a custom parser:
-PATTERN

To display only lines containing specific keywords, you can use the Pattern command. If you’re looking for more than one keyword, you can list them after the Pattern command separated by a comma.
Log file parsing is the process of analyzing log file data and breaking it down into logical metadata. In simple words – you’re extracting meaningful data from logs that can be measured in thousands of lines.
