
Every organization that handles large volumes of data should implement an archiving system to separate active from inactive data, including log files. With recent changes in data laws in the EU and the growing needs for log archiving, finding a quality file storage and archiving solution is more important than ever. We will discuss the reasons for archiving data and show you how to successfully store logs and use the Archive feature in Graylog Enterprise.
WHAT IS DATA ARCHIVING?
Data archiving is the process of moving inactive data to separate storage for long-term retention. This separates active data from data that is no longer in use but might be needed for future reference, often for legal reasons such as regulatory compliance.
Depending on the kind of data your company deals with, you may have a need for enterprise text archiving, e-commerce log archiving, email archiving, etc.
WHY SHOULD I ARCHIVE MY LOGS?
Reasons to archive logs:
- Optimizing data storage
- Regulatory compliance
- Data loss prevention
- Reducing storage costs
- Securing data against loss
DATA STORAGE OPTIMIZATION
When you archive data, you can use compression to save storage space, which can’t be done with active data since you would need to constantly perform decompression and compression. By separating active from inactive logs and automating the data archiving process, you ensure that the production systems run better and use fewer resources.
COMPLIANCE
Data compliance regulations require that your business keeps data for a certain period of time, regardless of whether it’s active or inactive. If your company is doing business in the European Union, you need to ensure compliance with GDPR. Effective from May 25, 2018, there have been significant changes to data protection law with fines for breaches of up to 20 million euro or 4% of total worldwide annual group turnover. This is a good reason to pick an efficient data archiving solution.
DATA LOSS PREVENTION
By storing all archived logs in a separate location, you secure them against data loss. Archives are accessed rarely and by qualified personnel only, which reduces the chances of an employee accidentally deleting valuable data.
COST REDUCTION
Active logs are kept in storage that is more expensive because it has better performance, namely speed and availability. Since you will rarely have to access archived logs, you can store them in a lower-tier storage type that costs significantly less and reduce your storage costs.
SECURITY
Archiving log data can increase security, which is especially important in case of cyber attacks and other security breaches. If an attack causes data loss, retrieving information from archived logs can help restore the system. Event logs contain data that can help increase security in many ways, and you can read more about it here. In some cases, you need to perform security forensics on logs that are months old, which is another reason to keep them in the archive instead of deleting them.

What Is Archive Log Backup?
There is a difference between data archive and backup – archiving makes a distinction between active and inactive data while backup simply makes a copy of all data – both active and inactive. This means that you can have an archive log backup, which is basically a copy of the whole archive. In case of a total system crash, you can restore Graylog Enterprise log data either by using the Graylog Enterprise Archiving feature or any other Elasticsearch backup and restore option.

Graylog Enterprise Archiving
The archiving feature in Graylog Enterprise enables you to archive log messages for a chosen retention period of time and re-import them into Graylog Enterprise on an at-need basis. Graylog Enterprise can be configured to automatically archive log messages to compressed flat files on the local filesystem. We use flat files because they are vendor-agnostic. Once you archive the log files, you can use them any way you need – store them in more affordable storage or print them out if you need physical archives.
Graylog Enterprise Archive Setup
Graylog Enterprise configuration options:
- Backend – backend on the master node where the archive files will be stored
- Max Segment Size – Maximum size in bytes of archive segment files
- Compression Type – Compression type that will be used to compress the archives
- Checksum Type – Checksum algorithm that is used to calculate the checksum for archives
- Restore Index Batch Size – Elasticsearch batch size when restoring archive files
- Streams to Archive – Streams that should be included in the archive
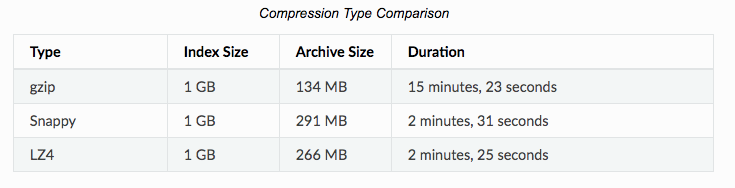
Creating Archives in Graylog Enterprise
You can create archives in Graylog Enterprise using any of the three ways:
- Web Interface
- Index Retention
- REST API
Web Interface
An archive can be created manually from the web interface on the Enterprise/Archives page. There is a form on the Create Archive for Index page where you can select and archive an index by clicking Archive Index. This will archive the index to the disk without deleting or closing it.
Index Retention
This option is the easiest way to automatically create archives without custom scripting. The index retention strategy can be used to automatically create archives before closing or deleting Elasticsearch indices.
REST API
If you need to customize the way you want to automate archive creation, Graylog Enterprise offers a REST API that enables you to do so. An index can be archived using a simple curl command shown in the image below:
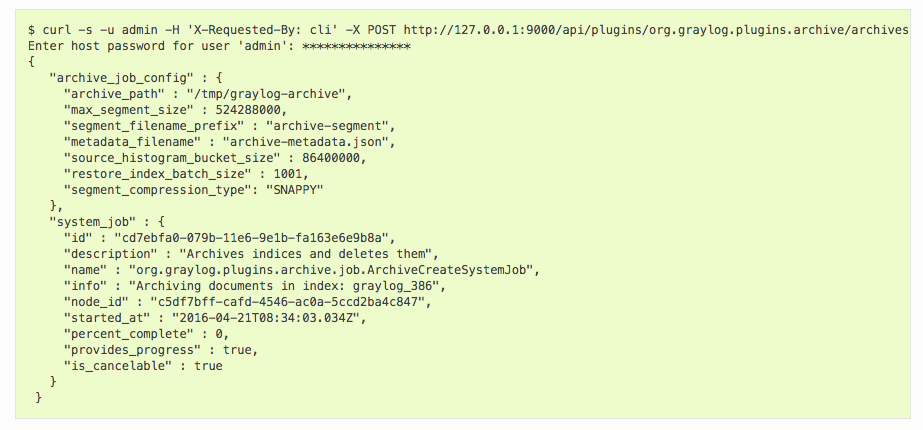
This command starts a system job in the Graylog Enterprise server to create an archive for index graylog_386. The system_job.id can be used to check the progress of the job. You can use the REST API to automate other archive related tasks such as updating the archive config or restoring and deleting archives.
For more information on the Graylog Enterprise Archiving feature, such as examples and FAQs, please read this text. You can also visit the Graylog Enterprise Marketplace to download an archive plugin for Elasticsearch or WebHDFS Output.
